TL;DR: The promise and risks of AGI will manifest well before we create a superintelligence. We can thus productively reflect on humanity’s catalogue of disasters to reason about AGI safety, classifying them on two dimentions:
existential vs non-existential disasters
intentional vs accidental disasters
History suggests that creating AGI carries the worst risks of nuclear and biological weapons, being both existential and accidental.
I conclude by summarizing the potential of LLMs to be engines of powerful autonomous, intelligent agents, indicating that this might be the right time to begin building AGI safety frameworks without engaging in speculation about superintelligence.
Special thanks for comments, edits, and feedback to Michael Schmatz, Nick Winter, Christopher Chow, and Brandon Iles.
Dalle-E image for the prompt: Sama looking in the mirror, seeing Yud as his reflection. Ukiyo-e.
Introduction
It was the op-ed read around the AI world. Elon Musk and others had signed a recently published open letter, now signed by over 13,000 others, calling “all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4.” In response, Elizier Yudkowsky, a researcher who for 20 years has been writing and speaking about the extinction risk posed by artificial general intelligence (AGI), instead called on us to “Shut it all down.” Citing the breakneck speed of recent advancements, he claimed that “We are not ready. We are not on track to be significantly readier in the foreseeable future. If we go ahead on this everyone will die.”
Other members of the AI industry were incensed by Yudkowsky’s letter. Some commentators, like my friend Collins Belton, criticized Yud for his support of preemptive airstrikes against data centers thought to be hosting risky AI research. Matt Palmer wrote a much-circulated rebuttal, in part arguing that Yud “and the other hardline anti-AI cultists are out of their depth, both in terms of command of basic technical elements of this field but also in terms of their emotional states.”
The cause for both the letter and its rebuttals was the attention generated by OpenAI’s ChatGPT, a chatbot that can understand and answer users through natural language text. ChatGPT is powered by large language models (LLMs), and the leap in abilities between OpenAI’s GPT-3 and GPT-4 raised concerns that future breakthroughs could be dangerous. One of my favorite authors is physicist Scott Aaronson, who mostly works on quantum computing. I was delighted to learn that he is currently on academic leave to work at OpenAI for one year on the “theoretical foundations of AI safety and alignment.” In response to the moratorium open letter he wrote, in his personal capacity, “Given the jaw-droppingly spectacular abilities of GPT-4—e.g., acing the Advanced Placement biology and macroeconomics exams, correctly manipulating images (via their source code) without having been programmed for anything of the kind, etc. etc.—the idea that AI now needs to be treated with extreme caution strikes me as far from absurd. I don’t even dismiss the possibility that advanced AI could eventually require the same sorts of safeguards as nuclear weapons.” I recommend reading his entire post, thoughtful as always.
The inspiration of Sam Altman.
A great irony is that OpenAI’s CEO Sam Altman, known simply as Sama, shares Yud’s beliefs about AGI. He describes the potential of AGI as basically indescribably infinite. Some of my Valley friends–who for some reason are the most talented programmers I know and also AI-doomers–used to jokingly say that Sama’s goal was to build God. Altman’s most recent interview in the WSJ again reinforced that angle. “The possibilities of AGI have led Mr. Altman to entertain the idea that some similar technology created our universe… He has long been a proponent of the idea that humans and machines will one day merge.”
Yud’s critics cannot dismiss him too lightly, given that that the leading AGI firm is led by a man that shares Yud’s belief about AGIs power. Sama and Yud are mirror images of each other. So the question remains, though. Is OpenAI building God? Or, as Musk likes to claim, is it summoning demons?
Heuristics, sources, and deep expertise. The intuition midwit curve.
I work in crypto and have zero hands-on experience building anything AI-related. But as a historian I can think of a few heuristics for thinking about its uncertainty and risk. Good heuristics are what allow some of us to survive in the left tail of the “midwit curve.” In this case, some of the risks presented by AI can be understood through humanity’s catalog of disasters, both historical and fictional.
I would like to pose two questions. First, is developing AGI like working at the Manhattan Project or at the Wuhan Virology Institute? Second, will AGI be intelligible or unintelligible to humans? That is, will it be more like the digital “children” in Ted Chiang’s Lifecycle of Software Objects with whom humans form various relationships, or will AGI be totally alien, submitting us to the “chain of suspicion” and mutual hostility, as dictated by the “cosmic sociology” in Liu Cixin’s The Dark Forest?
I find that approaching the question of superintelligence directly–as has been tradition within the Yudkowskian tradition–can trap discussions in unanchored speculation. Rather, I think the risks of AGI can be apprehended in a more piecemeal manner, anchored in our past experience with powerful new technologies as well as our current understanding of langauge and intelligence. These reflections could very well guide us to a framework for mitigating AGI well before it becomes a god-like superintelligence. In other words, we don’t need to know what superintelligence will be like. LLMs will be powerful engines for autonomous agents and plausibly require at least the same safeguards as nuclear and biological weapons research.
A Typology of Disaster
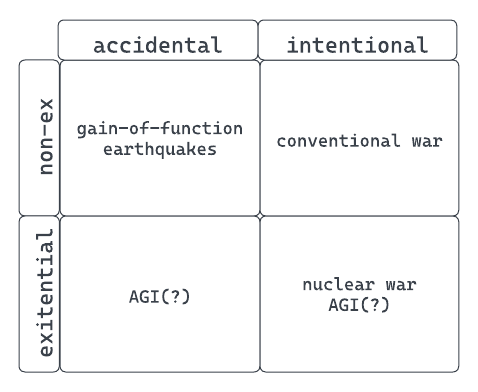
Imagine a two-by-two matrix that divides historical disasters into accidental or intentional, and into existential or non-existential. Existential meaning that it wipes out a country or civilization, or in the extreme, our species.
A typology of disaster.
Conventional wars are both intentional and non-existential. Intense periods of planning and great forethought go into the waging of conventional wars. They are often preceded by months if not years of diplomacy. More importantly, as devastating as conventional wars are, they are not existential to our species–we’ve survived thousands of them and millions of casualties.
Pandemics, such as COVID19, are non-existential and accidental (at least so far). The first carrier of a new pathogen becomes Patient Zero only in retrospect–no one knows when they are beginning a global pandemic. At the same time, pests and waves of disease have been a mainstay of human history, even when it seemed like the world was ending. Nuclear war, on the other hand, is both an intentional and existential disaster. A full nuclear exchange would precipitate a civilizational reset. All instances of Cold War brinkmanship reflect the overwhelming stakes and the need for human judgment about even the most minute details.
Yud is proposing that AGI is both an accidental and existential disaster risk. It is existential because “If somebody builds a too-powerful AI, under present conditions, I expect that every single member of the human species and all biological life on Earth dies shortly thereafter.” It is accidental because there is currently very little work to allow us to anticipate when a new AI system poses a risk of becoming an unaligned AGI.
So Which One is It?
OpenAI, in some ways, is like the Manhattan Project. It is highly focused, with a clear objective. There is a widespread belief that the country that develops this core technology will gain a decisive geopolitical edge. The complexity of ASIC and GPU supply chains resembles the complex chain of components and expertise required to build a nuclear bomb. That very complexity is what makes the Nuclear Non-Proliferation Treaty effective, as these supply chains offer chokepoints for the great powers to restrict technological diffusion. Historically, second-tier nuclear powers did not develop their own nukes, but relied on materials and expertise from the Soviets or the Americans.
In the future, if the field militarizes, AGI capability will be gated by the Americans and the Chinese. It is likely that advanced semiconductor manufacturing in some ways is significantly more complex than manufacturing nuclear weapons. For example, North Korea can manufacture a nuke. And yet, China is unlikely to replicate some of the technologies that make the latest semiconductors possible, as detailed in Chris Miller’s Chip War.
But there are important ways in which building AI is not at all like building nukes. For one, the efforts have been mostly led by private industry. In the United States, the top three AI labs are OpenAI, DeepMind, and Anthropic. However, one should not discount Google, which was for a long time the leader. Google’s AI lab, called Google Brain, produced the breakthrough in the transformer approach in their seminal 2017 paper “Attention is All you Need.” It is also worth noting that DeepMind is a unit of Google. For its part, OpenAI was founded in 2015 as a non-profit, focused primarily on video games and other applications. In 2018 it released the paper “Improving Language Understanding by Generative Pre-Training”—introducing the concept of a Generative Pre-trained Transformer (GPT), which forms the basis of GPTChat. A group of OpenAI employees left in 2021 and set up Anthropic, which is now backed and funded by Google.
Microsoft began cooperating with OpenAI in 2019, and might end up owning up to 50% of the for-profit entity within OpenAI, being unable to develop the underlying technologies itself. In some ways the idea that it could use AI to augment Bing to challenge Google in search is also far-fetched–Google had already been testing natural language retrieval and decided against it years ago, though the project lives on as the “Featured Snippets” on Google Search. The reason Google decided against LLM as a replacement for search is because although LLMs generate “correct-looking” answers, the LLMs are uninterpretable models prone to hallucination, making them hard to troubleshoot. Google’s machine intelligence division instead opted to rely on interpretable models that it could fine-tune to augment search, something that has taken years. One way to articulate the search problem is that it helps the user uncover knowledge about the world, so this makes LLMs obviously not a great candidate for information retrieval on their own.
China, the only other potential AI superpower, will similarly have to rely on the efforts of its private technology companies, even as they are more tightly under government influence than in the United States.
The Wuhan Institute of Virology.
But OpenAI is also like the Wuhan Virology Institute (WVI), the coronavirus research facility which is the origin of COVID19. WVI was set up in the aftermath of the SARS1 outbreak, which was a deadlier, but less transmissible coronavirus. WVI attracted researchers and funding for understanding the risks of these coronaviruses, whose natural reservoirs were determined to be cave-dwelling bats hundreds of miles away. The likely bat reservoir of the SARS1 virus was found, and thousands of other coronaviruses collected by eager researchers. Gain-of-function research, which modifies the viruses to make them more infectious to human tissue, was also carried out at WVI. Some have called this process a “self-licking ice cream cone,” that is, a bureaucratic runaway process that continues even though it serves no purpose.
There are some parallels with OpenAI. Sama himself has said that Yud’s writings on AGI strongly inspired him to co-found OpenAI. Writing on Twitter, Sama writes “eliezer has IMO done more to accelerate AGI than anyone else. certainly he got many of us interested in AGI, helped deepmind get funded at a time when AGI was extremely outside the overton window, was critical in the decision to start openai, etc.” He thinks that “it is possible at some point he [Yud] will deserve the nobel peace prize for this.” This, of course, reminds me that by fervently trying to prevent something we manifest it into being. This is like Cassandra causing others to fulfill her prophecy of doom by uttering it. Much like one of my favorite memes about self-fulfilling disaster–the parable of the Torment Nexus, which reads “Tech Company: At long last, we have created the Torment Nexus from classic sci-fi novel Don’t Create The Torment Nexus.” (below)
In this case, it is not OpenAI but Meta that is “Wuhan.” Meta released their own LLM, called LLaMA, a 65-billion parameter model, in February 2023. OpenAI had not open-sourced GPT3 or GPT4 out of fear that it could be misused. Meta, however, wanted to provide limited access to researchers and in the process their model ended up leaking a week after it was announced. Whoops. It can now be found on 4chan. The llama.cpp repo already has over 20,000 stars, and clearly more people have cloned it than have starred it. And that is just one port of the LLAMA model.
If we think that AI has some dangerous applications–not necessarily existential but harmful–then certainly we would eventually expect some sort of safety regime around AI research in the same way that we have biosafety standards.
But OpenAI as Wuhan is a sobering analogy. In theory, since the 1972 and 1975 Biological Toxin and Weapons Convention (BTWC) came into force, no state should possess nor seek to possess biological weapons. Biosafety standards for labs should also prevent the excape of dangerous pathogens being used for research. And yet we know that in both the US and USSR anthrax, smallpox, and other pathogens have repeatedly leaked through accidents. The Soviet program continued to grow into the 1990s, defectors revealed, since there were no means of documenting compliance. The US likely continued its own programs as well.
China too has suffered leaks from SARS1 and other coronaviruses. SARS1 escaped twice by 2004, in Beijing! What we must conclude is that weapons research continues under the guise of non-military research, and that the use of academic and private-sector partners to do this has make leaks and lab escapes distressingly common.
The most obvious failure of our currency biological regime is that even after the toll of COVID19 we still have not banned gain-of-function research. The bureaucratic state in the US under Anthony Fauci has succeeded at preserving itself, and has similarly succeeded in China at justifying its continued existence.
Biological safety and research might be too far gone to rescue. The lesson from history is that, despite posing an accidental “leak” risk, effective AI safety must avoid the same administrative structures and incentives that have rendered biological safety such an abject failure. It might be the case that
What is to be done?
So maybe working on AI is more like working at a cross of the Manhattan Project and the Wuhan Institute of Virology. This would suggest that treaty agreements might not be entirely ineffective. We have perhaps failed to prevent the creation of “self-licking ice cream cones” in the sciences–one could hope that COVID-19 will change that. But nuclear non-proliferation has been somewhat effective. It might be the distinct memory of the nuclear bombings of Hiroshima and Nagasaki that imbue nuclear controls with a seriousness and stringency that biological research currently lacks.
There is no doubt, though, that the long arm of the regulatory state is coming for AI in the US, and obviously too in China. President Biden on April 4, 2023, asked for the creation of an AI Bill of Rights to address the risks AI poses to the American people. At the present those efforts are more likely to be co-opted by”AI Safety” grift–that is, efforts around so-called “algorithmic bias” and other unimportant concerns powered by vague notions from identity politics. Almost nothing in teh current AI Bill of Rights is relevant to extinction risk. But that will change once we have an AI-related accident, which the media will breathlessly cover. Those airstrikes on GPU farms might come sooner than we think.
But is it risky?
Sure, the government might want to regulate AI, just like it does any other technology that receives any attention (such as crypto). But just how risky are current LLMs?
Prediction markets on Metacalclus are now showing AGI somewhere in 2032, decades earlier than before. As is the nature of potentially exponential improvement, 2032 will turn out to be woefully too late or too soon for AGI–meaning, if we are on a path to AGI it will likely arrive well before 2032. Alternatively, if we are not on the path to AGI then it will arrive much later than 2032.
According to a survey of researchers at MIRI, OpenAI, DeepMind, the Future of Humanity Institute, the Center for Human-Compatible AI, and Open Philanthropy, the median AI expert thinks that AGI has a 30% chance of destroying the world. This isn’t just your average technology. There are good a priori reasons for proceeding with caution.
LLMs as engines for intelligent, autonomous actors
As promised, we will not engage with the question of superintelligence. Rather, I believe the promise and shape of AGI is worth exploring through a look at the ability of LLMs to serve as engines for powerful intelligent, automous agents. So let us first consdier their ability to extract enough knowledge from human text to train an AGI. Second, we will consider their ability to create agents.
My undergraduate studies were in modal and diagrammatic logics (another reason I’m partial to Aaronson’s writings on quantum computing), and so I’ve found I am partial to what has been called the “latent space hypothesis.” That is, the idea that core elements of human logic and intelligence are embedded or “latent” in our collective textual corpus, which matters because LLMs and other AI models are quite good at finding latent space representations in data. Winograd schemes are also great at illustrating the world knowledge latent in text.
This concept is relatively straightforward, so I’ll explain with an anecdote. As a member of my best friend’s wedding party last year, I observed as the group pulled out an unfamiliar board game in a cabin overlooking Half Moon Bay. I wasn’t playing, so after a few rounds they offered to explain the rules to me. I declined, replying that I was trying to see how many rounds I would have to observe before I could deduce the game’s rules. Half of those present were Stanford computational linguistics PhDs, so this quip proved more amusing than it should have been and temporarily derailed game night. But this is, in a way, the latent space hypothesis. Looking only at the textual evidence left behind by humans about the world, could an LLM decipher not only how humans think and learn, but also learn what their world was like?
I think there is a high likelihood that an LLM could be adapted to reconstruct some level of generalizable intelligence from vast amounts of human text. But it would seem that there are limits to this–at some point the AI would need a way to conduct experiments with inputs and outputs into the real world. If LLMs are limited to interactions with humans through text input and output, then it seems like what LLMs will end up being really good at is understanding people–or the world through human eyes. Uber claimed it was a company that could move both bits AND atoms. OpenAI might better be described as a company that will be very good at moving people, much as a zookeeper can learn through trial and error how to interpret the behavior and motives of his animals.
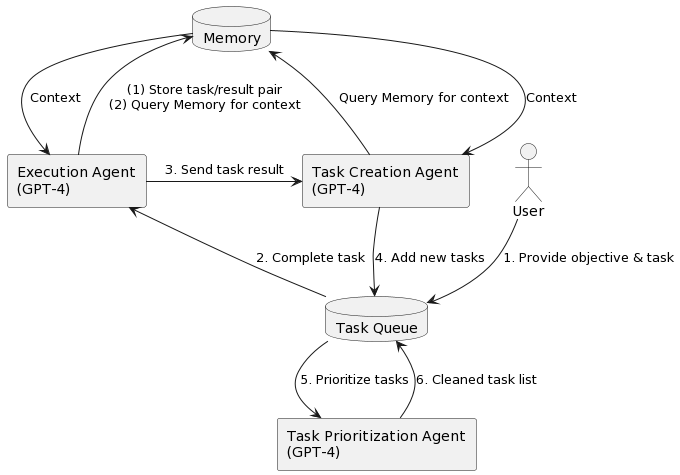
On the question of whether LLMs can be agentic, I’ll confess that I’ve been learning what others have been doing online. Yohei Nakajima’s work wiring up simple and then parallel agents using GPT4 has been nothing short of fascinating, if anything because it happened over just a couple of weeks. Yohei, both a GP at Untapped VC and a talented engineer, originally aimed to wire up an “AI Founder,” that is, an autonomous agent that could not only complete tasks assigned to it, but could create and prioritize new tasks for itself. A pared-down version of his code, called BabyAGI, was just released a few days ago. It focuses entirely on making “three task agents (execution, creation, prioritization) work in harmony… forever” based on a general objective. For some fun examples, watch this short video of Yohei instructing his agent to “build and grow a mobile AI startup.”
So while LLMs themselves might not be spontaneously agentic or volitional, it is now clear from the public’s experimentation that LLMs can be a powerful engine for autonomous agents.
One might be forgiven for thinking that, given the massive expense involved in creating AI, autonomous agents cannot pose a huge risk. Well, that might be the case when it comes to training a model, but the models themselves do not need to be that big after they are trained. Meta’s leaked LLaMA was first optimized to run on a regular consumer laptop. Then Georgi Gerganov released llama.cpp which can run, offline, on a Raspberry Pi, the popular microcomputers that fit in the palm of your hand.
A simple analogy can illuminate this process. Human brains are born pre-trained to acquire language, shapes, emotions. The brains of other species come pre-trained for different talents. All living intelligences come pre-trained by billions of years of evolution, which is a simple but very expensive algorithm for producing and training intelligence. In comparison, new human intelligence is relatively easy to produce–just nine months and a few years of nurture is all it takes.
In my view, it is still too early to accurately assess the risks that AGI might pose, and it is also too early to tell what the costs of human misuse of AI could be.
And if it thinks… Edenic Menagerie or Dark Forest?
If AGI does emerge, it could take one of two shapes. One the one hand we have the digients from Ted Chiang’s Lifecycle of Software Objects. The novella describes artificial intelligences almost like baby mammals that have to be educated, nurtured, and loved to grow. If we think that AGI will train itself on the latent space in humanity’s writings (or a selection thereof) then it is possible that it might be imbued with an intelligence that is intelligible to us, even if it is never “inferior” to humans as in Chiang’s story. If Sama triumphs in building “God”, then it would be ironic that AGI would end up being a reflection of its inferior human creators.
Digients growing up in Chiang's Lifecycle of Software Objects.
Yud’s terror is that AGI, however we train it, will be as wholly alien and unintelligible as a spider or slime mold. The fictional analogy becomes Liu Cixin’s Dark Forest. Liu posits two principles in cosmic sociology: that survival is the primary objective of any civilization, and that the finite nature of cosmic resources indicates that they are in competition with each other. This then traps civilizations in a chain of suspicion, where two alien civilizations cannot discern the honest intention of the other, and thus must decide to destroy the other. What could be a greater obstacle to discerning intention than mutual intelligibility?
Conclusion
AGI will be an unprecedented technology, according to Yud and Sama, the twin prophets of AI doom and salvation. Looking to humanity’s catalogue of past disasters, it does look like a hybrid of the Manhattan Project, the Wuhan Virology institute, and Facebook. Doomers might find it soothing to think about the complex supply chains, the possibility of a joint Sino-American treaty, and the public discourse about AI risk (versus the nonexistent debate around biosafety). But doomers might continue to worry that AI leaks could prove as accidental and random as pathogen leaks, and that autonomous agents and small models might be as impossible to eradicate once they are set free in the world.
Yud, Sama, and Grimes taking a selfie in San Francisco. Only Elon's missing from the group shot.
The one ray of hope is that Elon Musk, another OpenAI co-founder, might be right and we do live in a simulation. The rules of the simulation are, as always, that the most amusing outcome is the most likely. How else to explain Sama’s selfie with Yud and Elon’s ex-girlfriend, Grimes just a month ago? I even asked ChatGPT to write me a joke based on the picture. “Elizier Yudkowsky, Sam Altman, and Grimes walk into a bar. The bartender looks up and says, ‘What is this, some kind of rationalist/transhumanist/techno-utopian joke?'”
GPTChat, that is a very good question. Sadly, you don’t have the answer. Yet.